之前整理了一遍http1.0, http1.1, http2.0之前的区别,但是里面很多细节都没有弄清。特别是在http1.1和2.0之间关于多路复用,头压缩这一块儿。 最近在外网上搜到一遍蛮详细的文章,觉得讲的很清晰,所以就翻译了分享给大家。原文地址
背景
在比较http2 和http1.1区别之前,让我们先宏观的看一看两者历史性的发展。
HTTP1.1
1989年作为万维网交流标准,属于应用层协议,在客户端和服务器端进行信息交换。这个过程中,客户端发送一个基于文本的请求到服务器通过调用GET 或者POST方法。 相应的,服务器返回资源给客户端。
例如:
GET /index.html HTTP/1.1
Host: www.example.com
该请求用GET方法。 服务器会返回一个HTML页面和一些图片,样式表和一些其他资源。注意:所有的资源并不是一次性返回给客户端。两者会在之间反反复复进行几次请求和响应,直到该html页面所有的资源内容在你的屏幕上被绘制。
HTTP/2
http2 刚开始为SPDY协议,起初Google为了减少加载延迟而开发的,通过使用例如压缩,多路复用,优化等。 目前该协议已经被很多浏览器所支持。
从技术角度而言,http1.1和2.0 最大的区别是二进制框架层。与 http1.1把所有请求和响应作为纯文本不同,http2 使用二进制框架层把所有消息封装成二进制,且仍然保持http语法,消息的转换让http2能够尝试http1.1所不能的传输方式。
Http1.1 流水线和队头阻塞
客户端首次接受的响应常常不能完全渲染。相反,它包含一些其他需要的资源。 因此,客户端必须发出一些其他请求。 Http1.0客户端的每一个请求必须重新连接,这是非常耗时和资源的。
Http1.1 通过引入长连接和流水线技术处理了这个问题。 通过长连接,http1.1假定这个tcp连接应该一直打开直到被通知关闭。 这就允许客户端通过同一连接发送多个请求。不巧的是,这优化策略有个瓶颈。当一个队头的请求不能收到响应的资源,它将会阻塞后面的请求。这就是知名的队头阻塞问题。虽然添加并行的tcp连接能够减轻这个问题,但是tcp连接的数量是有限的,且每个新的连接需要额外的资源。
Http2 二进制框架层的优势
在http2 , 二进制框架层编码 请求和响应 并把它们分成更小的包,能显著的提高传输的灵活性。
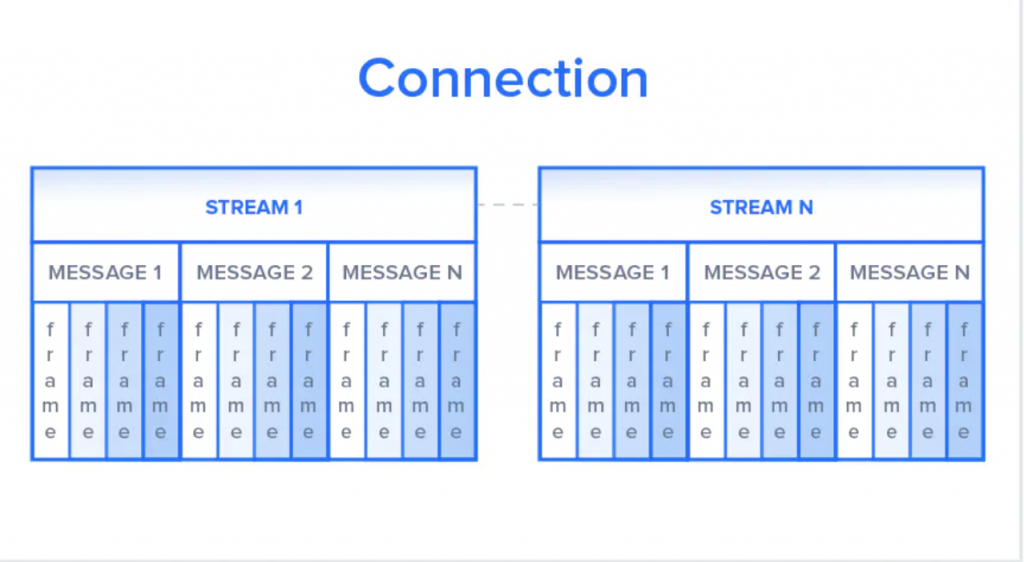
与http1.1利用多个tcp连接来减少队头阻塞的影响相反,http2在两端建立一个单独的连接。该连接包含多个数据流。 每个流包含多个请求/响应格式的消息 。 最终,每个消息被划分为更小的帧单元。
1.png
在最细微层面上,交流通道由一系列二进制帧组成,每一个被标记到特定的流。可识别标签允许连接在传输过程中来交错这些帧并在另一端去组合它们。 交错的请求和响应能够并行的传输而不被阻塞。该过程被称作多路复用技术。
因为多路复用允许客户端并行的构建多个流,这些流仅仅需要一个tcp连接。 相比http1.1能很大程度上减少内存和整个网络中的足迹。所以有更好的网络及带宽利用率。
Tcp连接也能改善https协议的性能,因为客户端可针对多个请求/响应 复用同一个连接 在tls和ssl握手期间,双方在整个会话同意使用唯一的key。 如果连接中断,新的会话需要一个新生成的key。 因此,维持单链接能很大程度优化https。
Http2 流的优先级
流优先级不仅仅解决同一资源的竞态问题,也允许开发人员自定义请求的权重。
如你所知,二进制框架层把消息组织成并行数据流。 当一个客户端发送并行请求,它能把请求的响应设置优先级权重 ,从1-256 ,更高的数字代表更高的优先级。 此外,该客户端也通过特定的流ID指明每个流的依赖。如果id被忽略,说明这个流是根流。

2.png
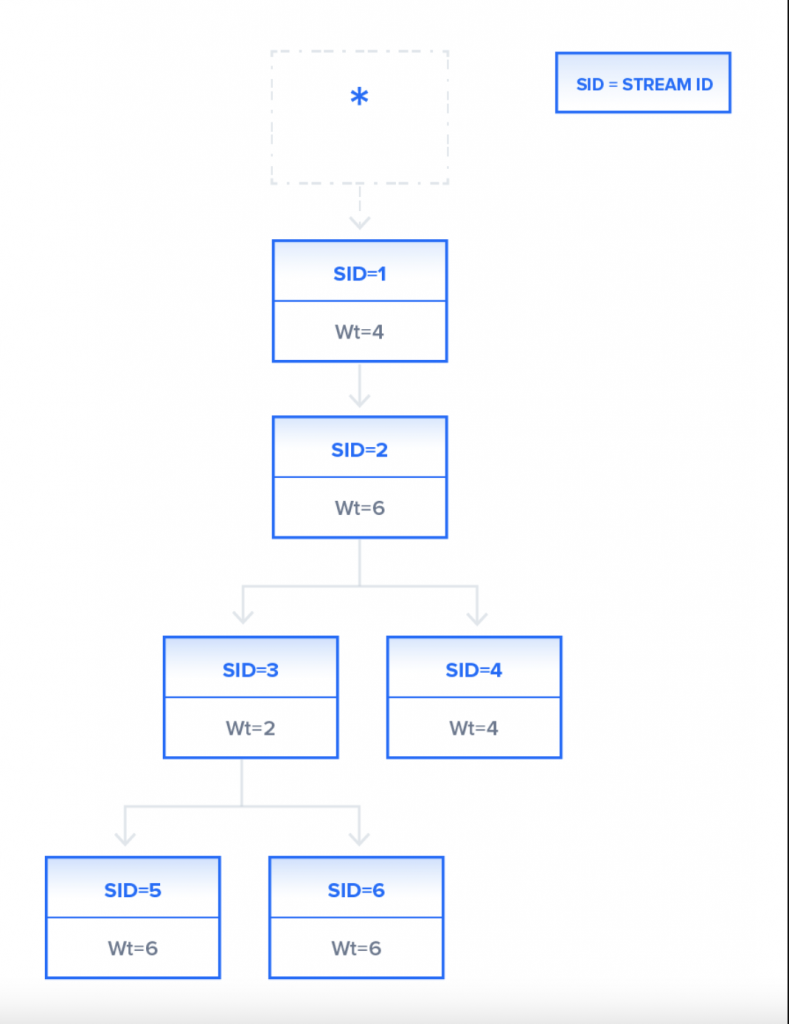
上图中,channel包含6个流,每个有一个唯一id 且有一个特定的权重。 流1没有父ID,说明是根节点。分配给每个流的资源将根据权重和它们需要的依赖。
服务器端利用该信息创建一个依赖树,通过次树来决定响应的数据。根据之前的图表,依赖树如下:
3.png
根据此依赖树,所有可用资源将会先分配给 流1。 因为流2依赖流1,流2直到流1完成后才处理。流2完成后,资源分配给流3,流4. 两者权重比为2:4,资源也会依此来分配。3,4完成后,流5,流6将会等分资源。
作为开发者,你可以根据需要去设置权重,例如,给高分辨率图片设置低优先级。Http2协议允许客户端在运行时根据用户交互重新分配权重和改变依赖。 然而,服务器端会改变优先级根据如果某个流因为请求特定资源被阻塞。
缓冲区溢出
客户端和服务器都有一定数量的缓冲区来持有还未被处理的请求。
当服务器返回给客户端一大堆数据,或者客户端上传一个大的图片和视频,可能造成缓冲区溢出。
为了避免缓冲区溢出,流控制机制可以禁止发送者发送太多数据。下面我们聊聊http1.1和http2不同的流控制机制。
Http1.1
http1.1流控制基于tcp连接。当连接建立时,两端通过系统默认机制建立缓冲区。 并通过ack报文来通知对方接收窗口大小。
因为Http1.1 依靠传输层来避免流溢出,每个tcp连接需要一个独立的流控制机制。
Http2
http2通过一个连接来多路复用。 结果是在传输层的tcp连接不足以管理每个流的发送。http2允许客户端和服务器端实现他们自己的流控制机制,而不是依赖传输层。两端在传输层交换可用的缓冲区大小,来让他们在多路复用流上设置自己的接收窗口。
预测资源请求
通常web应用,客户端发送一个GET请求且收到一个HTML。当检测收到html的内容,会发现它需要拿取其他的资源。例如CSS和JS文件。然后就会继续请求其他资源。这些请求会最终加长连接加载时间。
解决办法:因为服务器端提前知道客户端需要额外资源,服务器端可以通过提前发送这些资源给客户来节省时间,而不用客户来请求。
Http/1.1 资源内联
如果开发者提前知道客户机器需要哪些额外的资源来渲染界面,他们使用资源内联的技术来包含需要的资源。例如:如果一个客户需要一个特定的CSS文件,内联该文件就可以不通过请求来拿到,减少客户端必须发送的请求数。
该技术对于小文件是可行的,但是大文件会降低连接的速度。还可能造成文件多次请求。
Http2 服务器推送
因为http2支持多个并发响应,服务器可以提前把HTML 页面中的其他资源在客户端请求之前发给它。
服务器先发送一个PUSH_PROMISE 帧通知客户端将推送资源。该帧只包含头消息,且允许用户提前知道哪些资源将会推送。如果客户端已经缓存,可以拒绝该推送。
压缩技术
常用的优化web应用是用压缩算法减少HTTP消息大小。 HTTP/1.1 和2 都用该技术HTTP/1.1不支持整个消息压缩。下面我们来聊聊区别。
Http1.1
Gzip已经被用于压缩http消息很久了,特别是减少CSS和JS脚本的文件。然而消息头部分依然是纯文本发送。尽管每个头都很小,但随着请求越来越多,连接的负担就会越重,如果带了cookie. Header将变得更大。
Http2
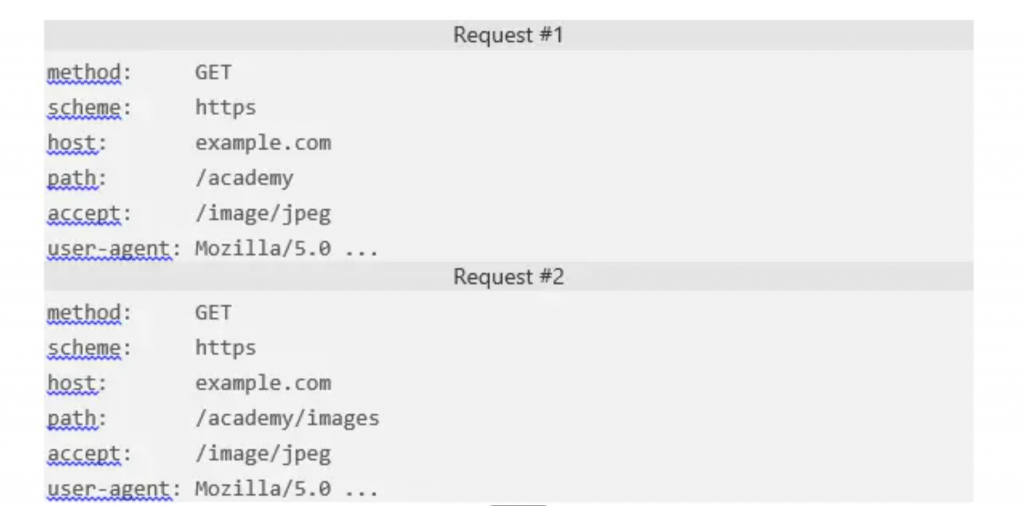
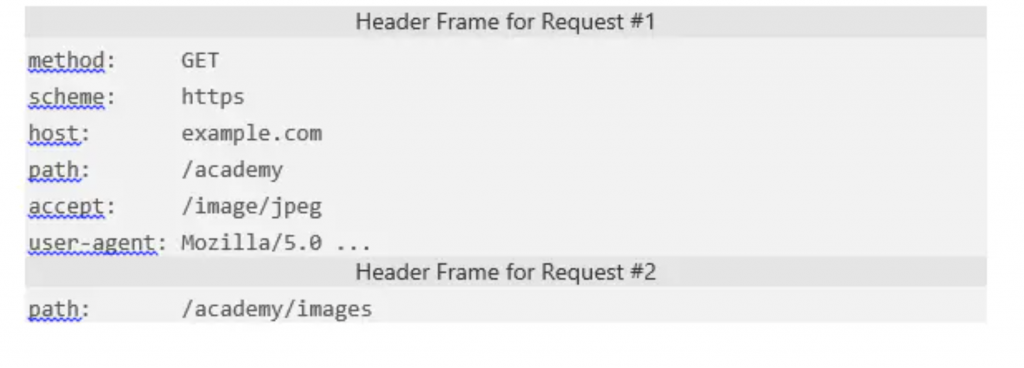
Http2 的二进制框架层在细节上表现出强大的控制力,在头压缩上也是如此。 http2 能把头从他们的数据中分离,并封城头帧和数据帧。 http2特定的压缩程序HPACK可以压缩头帧。 该算法用Huffman编码头metadata,可以很大程度上减少头大小。此外, HPACK可以跟踪先前传输的metadata字段,然后通过动态改变服务器端和客户端共享的索引来进一步压缩。如下:
4.png
如上图,上述字段只有path有不同的值。 因此,HPACK可以只发送需要改变的值
5.png
此外:
关于Https,Http1.0, 1.1, 2.0的区别,可以参考这篇文章
关于tcp,udp报文讲解和分析,可以参考这里
关于tcp,udp 三次握手和四次挥手,可以参考这里6人点赞网络基础
作者:CyrusChan
链接:https://www.jianshu.com/p/63fe1bf5d445
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
转载请注明:学时网 » 详细分析http2 和http1.1 区别