当前是云计算和数据快速增长的时代,今天的应用程序正以PB级和ZB级的速度生产数据,但人们依然在不停的追求更高更快的性能需求。随着数据的堆积,如何快速有效的搜索这些数据,成为对后端服务的挑战。本文,我们将比较业界两个最流行的开源搜索引擎,Solr和ElasticSearch。两者都建立在Apache Lucene开源平台之上,它们的主要功能非常相似,但是在部署的易用性,可扩展性和其他功能方面也存在巨大差异。
关于Apache Solr
Apache Solr基于业界大名鼎鼎的java开源搜索引擎Lucene,Lucene更多的是一个软件包,还不能称之为搜索引擎,而solr则完成对lucene的封装,是一个真正意义上的搜索引擎框架。在过去的十年里,solr发展壮大,拥有广泛的用户群体。solr提供分布式索引、分片、副本集、负载均衡和自动故障转移和恢复功能。如果正确部署,良好管理,solr就能够成为一个高可靠、可扩展和高容错的搜索引擎。不少互联网巨头,如Netflix,eBay,Instagram和Amazon(CloudSearch)均使用Solr。
solr的主要特点:
-
全文索引
-
高亮
-
分面搜索
-
实时索引
-
动态聚类
-
数据库集成
-
NoSQL特性和丰富的文档处理(例如Word和PDF文件)
关于Elasticsearch
与solr一样,Elasticsearch构建在Apache Lucene库之上,同是开源搜索引擎。Elasticsearch在Solr推出几年后才面世的,通过REST和schema-free(不需要预先定义 Schema,solr是需要预先定义的)的JSON文档提供分布式、多租户全文搜索引擎。并且官方提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript客户端。
分布式搜索引擎包含可以华为为分片(shard)的索引,每一个分片可以有多个副本(replicas)。每个Elasticsearch节点可以有一个或多个分片,其引擎既同时作为协调器(coordinator ),将操作转发给正确的分片。
Elasticsearch可扩展为准实时搜索引擎。其中一个关键特性是多租户功能,可根据不同的用途分索引,可以同时操作多个索引。
Elasticsearch主要特性:
-
分布式搜索
-
多租户
-
查询统计分析
-
分组和聚合
热度对比
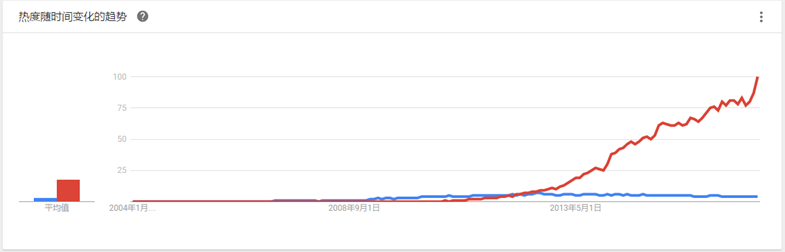
在开始比较前,我们可以查看两者在google中的搜索热度,可以看出在2013年后,Elasticsearch与Solr相比具有很大的吸引力,但这并不意味着Apache Solr已经死了。虽然不少人不认可,但Solr仍然是最流行的搜索引擎之一,具有强大的开源社区支持。
安装与配置
相对来说,Elasticsearch更易于安装,与Solr相比非常轻量级。 Solr的分发软件包大小的当前版本(6.4.2)大约为150 MB,而Elasticsearch分发软件包大小的当前版本(5.2.2)仅为32.2MB。
但是,如果Elasticsearch管理不好,这种易于部署和使用可能会成为一个问题。基于JSON的配置很容易,但如果你想为文件中的每个配置指定注释,那么它不适合你。Solr也提供了Rest API,可以通过集合API创建自定义分片集合,记录聚类算法和执行自定义分片。
总的来说,如果你的应用程序使用JSON,那么Elasticsearch是一个更好的选择。否则,使用Solr,因为它的schema.xml和solrconfig.xml有很好的文档。
索引和搜索
数据源
Solr接受来自不同来源的数据,包括XML文件,逗号分隔符(CSV)文件和从数据库中的表提取的数据以及常见的文件格式(如Microsoft Word和PDF)。
Elasticsearch还支持其他来源的数据,例如ActiveMQ,AWS SQS,DynamoDB(Amazon NoSQL),FileSystem,Git,JDBC,JMS,Kafka,LDAP,MongoDB,neo4j,RabbitMQ,Redis,Solr和Twitter。还有各种插件可用。
搜索
Solr专注于文本搜索,而Elasticsearch则常用于查询、过滤和分组分析统计,Elasticsearch背后的团队也努力让这些查询更为高效。因此当比较两者时,对那些不仅需要文本搜索,同时还需要复杂的时间序列搜索和聚合的应用程序而言,毫无疑问Elasticsearch是最佳选择。
索引
两者都支持使用停用词和同义词来匹配文档。
在Solr中,索引间进行join必须是单个分片和其他节点上的副本集进行关联来搜索文档间关系(例如SQL连接)。而Elasticsearch提供更高效的has_children和top_children查询来检索这样的相关文档。
可扩展性和分布式
搜索引擎需要处理数以百万级的文档,基于此搜索引擎应该是可复制的,模块化的和可扩展的,支持集群和分布式架构。
专为云而设计
Elasticsearch非常易于扩展,拥有足够多的需要大集群的使用案例。
Solr 基于Apache ZooKeeper也实现了类似ES的分布式部署模式。ZooKeeper是成熟和广泛使用的独立应用程序。
相对比,Elasticsearch有一个内置的类似ZooKeeper的名为Zen的组件,通过内部的协调机制来维护集群状态。
可以说Elasticsearch是转为云而设计,是分布式首选。
分片拆分和再平衡
shards是luence索引的分区单元,solr和elasticsearch均使用。你可以通过在集群中的不同计算机上运行shard来分发索引。随着SolrCloud的引入,Solr开始支持shard拆分,这允许您通过拆分现有shard来添加更多shard。相比之下,ElasticSearch仍然不支持这一点,事实上,实际上阻止了这种做法。ES通过向设置中添加更多计算机,可以使用自动碎片平衡功能。相比之下,Solr允许添加分片(使用隐式路由时)或分割(使用复合ID时),但不能删除分片。它允许您增加副本。在Elasticsearch中,默认情况下每个索引具有五个分片。它不允许您更改主分片的数量,但它允许您增加副本的数量。分片再平衡对于水平扩容非常有用。当添加新机器时,它将自动重新平衡不同机器中可用的分片。
社区
Solr有一个广泛的开源社区。任何人都可以贡献给Solr,新的Solr开发人员或代码提交者只能根据功能选择。 Elasticsearch在技术上是开源的,但不完全。所有贡献者都可以访问源代码,用户可以进行更改并提供。但最终的变化由Elastic(运行Elasticsearch和其他软件的公司)的员工确认和完成。因此,Elasticsearch更多地由单个公司驱动,而不是整个社区。
Solr贡献者和提交者跨越多个组织,而Elasticsearch提交者仅来自Elastic。还有人指出,Solr的强大社区有一个健康的项目管道和许多知名公司参与。这些成员还通过在整个开发和工程过程中做出贡献来投资该平台。
两者都有很好的用户群和丰富的开发人员社区,但ElasticSearch相较于Solr更新。 Solr已经存在了更长的时间,所以它的生态系统是发达的,拥有更大的用户群。
文档
Solr在这里得分很高。它是一个非常有据可查的产品,具有清晰的示例和API用例场景。 Elasticsearch的文档组织良好,但它缺乏好的示例和清晰的配置说明。
选Solr 还是 Elasticsearch?
通过上面的对比,很难确定谁是最终赢家。其实,无论选择Solr还是Elasticsearch,你首先需要了解您的用户场景和未来的需求。我们来总结一下:
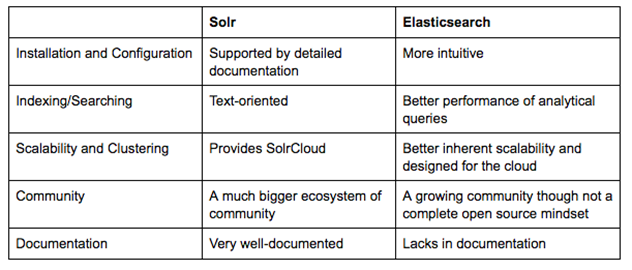
请记住:
-
Elasticsearch由于其易用性而在较新的开发人员中更受欢迎
-
但是如果你已经在使用solr了,请继续使用它,因为迁移到Elasticsearch并不会带来具体的优势
-
如果您需要它来处理分析查询以及搜索文本,Elasticsearch是更好的选择,特别是收集日志,做分析处理(参考前面发的ELK 安装使用http://www.cnblogs.com/xiaoqi/p/elk-part1.html)
总之,两者都是功能丰富的搜索引擎,并且或多或少地给出相同的性能,只要它们被设计和实施得很好。
本文主要内容为翻译http://logz.io/blog/solr-vs-elasticsearch/,感谢作者,感谢谷歌翻译!
Hermes与开源的Solr、ElasticSearch的不同
谈到Hermes的索引技术,相信很多同学都会想到Solr、ElasticSearch。Solr、ElasticSearch在真可谓是大名鼎鼎,是两个顶级项目,最近有些同学经常问我,“开源世界有Solr、ElasticSearch为什么还要使用Hermes?”
在回答这个问题之前,大家可以思考一个问题,既然已经有了Oracle、MySQL等数据库为什么大家还要使用Hadoo[下的Hive、Spark? Oracle和MySQL也有集群版,也可以分布式,那Hadoop与Hive的出现是不是多余的?
Hermes的出现,并不是为了替代Solr、ES的,就像Hadoop的出现并不是为了干掉Oracle和MySQL一样。而是为了满足不同层面的需求。
一、Hermes与Solr,ES定位不同
Solr\ES :偏重于为小规模的数据提供全文检索服务;Hermes:则更倾向于为大规模的数据仓库提供索引支持,为大规模数据仓库提供即席分析的解决方案,并降低数据仓库的成本,Hermes数据量更“大”。
Solr、ES的使用特点如下:
1. 源自搜索引擎,侧重搜索与全文检索。
2. 数据规模从几百万到千万不等,数据量过亿的集群特别少。
Ps:有可能存在个别系统数据量过亿,但这并不是普遍现象(就像Oracle的表里的数据规模有可能超过Hive里一样,但需要小型机)。
Hermes:的使用特点如下:
1. 一个基于大索引技术的海量数据实时检索分析平台。侧重数据分析。
2. 数据规模从几亿到万亿不等。最小的表也是千万级别。
在 腾讯17 台TS5机器,就可以处理每天450亿的数据(每条数据1kb左右),数据可以保存一个月之久。
二、Hermes与Solr,ES在技术实现上也会有一些区别
Solr、ES在大索引上存在的问题:
1. 一级跳跃表是完全Load在内存中的。
这种方式需要消耗很多内存不说,首次打开索引的加载速度会特别慢.
在Solr\ES中的索引是一直处于打开状态的,不会频繁的打开与关闭;
这种模式会制约一台机器的索引数量与索引规模,通常一台机器固定负责某个业务的索引。
2. 为了排序,将列的全部值Load到放到内存里。
排序和统计(sum,max,min)的时候,是通过遍历倒排表,将某一列的全部值都Load到内存里,然后基于内存数据进行统计,即使一次查询只会用到其中的一条记录,也会将整列的全部值都Load到内存里,太浪费资源,首次查询的性能太差。
数据规模受物理内存限制很大,索引规模上千万后OOM是常事。
3. 索引存储在本地硬盘,恢复难
一旦机器损坏,数据即使没有丢失,一个几T的索引,仅仅数据copy时间就需要好几个小时才能搞定。
4. 集群规模太小
支持Master/Slave模式,但是跟传统MySQL数据库一样,集群规模并没有特别大的(百台以内)。这种模式处理集群规模受限外,每次扩容的数据迁移将是一件非常痛苦的事情,数据迁移时间太久。
5. 数据倾斜问题
倒排检索即使某个词语存在数据倾斜,因数据量比较小,也可以将全部的doc list都读取过来(比如说男、女),这个doc list会占用较大的内存进行Cache,当然在数据规模较小的情况下占用内存不是特别多,查询命中率很高,会提升检索速度,但是数据规模上来后,这里的内存问题越来越严重。
6. 节点和数据规模受限
Merger Server只能是一个,制约了查询的节点数量;数据不能进行动态分区,数据规模上来后单个索引太大。
7. 高并发导入的情况下, GC占用CPU太高,多线程并发性能上不去。
AttributeSource使用了WeakHashMap来管理类的实例化,并使用了全局锁,无论加了多大的线程,导入性能上不去。
AttributeSource与NumbericField,使用了大量的LinkHashMap以及很多无用的对象,导致每一条记录都要在内存中创建很多无用的对象,造成了JVM要频繁的回收这些对象,CPU消耗过高。
FieldCacheImpl使用的WeakHashMap有BUG,大数据的情况下有OOM的风险。
单机导入性能在笔者的环境下(1kb的记录每台机器想突破2w/s 很难)
Solr与ES小结
并不是说Solr与ES的这种方式不好,在数据规模较小的情况下,Solr的这种处理方式表现优越,并发性能较好,Cache利用率较高,事实证明在生产领域Solr和ES是非常稳定的,并且性能也很卓越;但是在数据规模较大,并且数据在频繁的实时导入的情况下,就需要进行一些优化。
Hermes在索引上的改进:
1. 索引按需加载
大部分的索引处于关闭状态,只有真正用到索引才会去打开;一级跳跃表采用按需Load,并不会Load整个跳跃表,用来节省内存和提高打开索引的速度。Hermes经常会根据业务的不同动态的打开不同的索引,关闭那些不经常使用的索引,这样同样一台机器,可以被多种不同的业务所使用,机器利用率高。
2. 排序和统计按需加载
排序和统计并不会使用数据的真实值,而是通过标签技术将大数据转换成占用内存很小的数据标签,占用内存是原先的几十分之一。
另外不会将这个列的全部值都Load到内存里,而是用到哪些数据Load哪些数据,依然是按需Load。不用了的数据会从内存里移除。
3. 索引存储在HDFS中
理论上只要HDFS有空间,就可以不断的添加索引,索引规模不在严重受机器的物理内存和物理磁盘的限制。容灾和数据迁移容易得多。
4. 采用Gaia进行进程管理(腾讯版的Yarn)
数据在HDFS中,集群规模和扩容都是一件很容易的事情,Gaia在腾讯集群规模已达万台)。
5. 采用多条件组合跳跃降低数据倾斜
如果某个词语存在数据倾斜,则会与其他条件组合进行跳跃合并(参考doclist的skip list资料)。
6. 多级Merger与自定义分区
7. GC上进行了一些优化
自己进行内存管理,关键地方的内存对象的创建和释放java内部自己控制,减少GC的压力(类似Hbase的Block Buffer Cache)。
不使用WeakHashMap和全局锁,WeakHashMap使用不当容易内存泄露,而且性能太差。
用于分词的相关对象是共用的,减少反复的创建对象和释放对象。
1kb大小的数据,在笔者的环境下,一台机器每秒能处理4~8W条记录.
转载请注明:学时网 » 分布式搜索和分析引擎对比



