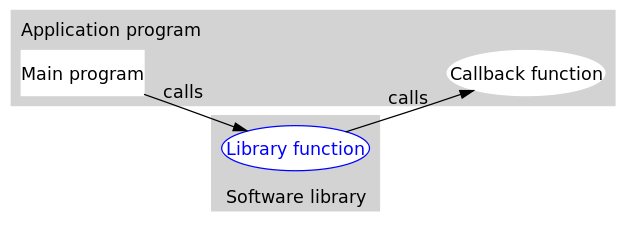
什么是回调函数?
我们绕点远路来回答这个问题。
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程...
8年前 (2018-11-14) 3167℃ 0评论
0喜欢
sql语法的分析是从右到左一、sql语句的执行步骤:1)语法分析,分析语句的语法是否符合规范,衡量语句中各表达式的意义。2)语义分析,检查语句中涉及的所有数据库对象是否存在,且用户有相应的权限。3)视图转换,将涉及视图的查询语句转换为相应的对基表查询语句。4)表达式转换, 将复杂...
8年前 (2018-11-13) 3153℃ 0评论
0喜欢
volatile 是保证了可见性还是有序性?
有序性:是因为 instance = new Singleton(); 不是原子操作。编译器存在指令重排,从而存在线程1 创建实例后(初始化未完成),线程2 判断对象不为空,但实际对象扔为空,造成错误。
可见性:是因为线程1 创建实...
8年前 (2018-10-30) 3232℃ 0评论
0喜欢
根分区只读后,根分区被umount
1、mount:
用于查看哪个模块输入只读,一般显示为:
/dev/hda1 on / type ext3 (rw)
none on /proc type proc (rw)
usbdevfs on /proc/bus/u...
8年前 (2018-10-22) 3075℃ 0评论
0喜欢
我们在写程序时,有不少时间都是在看别人的代码。 例如看小组的代码,看小组整合的守则,若一开始没规划怎么看, 就会看得云山雾罩不知其所然。
不管是参考也好,从开源抓下来研究也好,为了了解箇中含意,在有限的时间下,不免会对庞大的源代码解读感到压力。
以下来介绍一下读代码的心法:
...
8年前 (2018-10-10) 2827℃ 0评论
0喜欢
前言
在讨论之前,首先要明白一个Java类加载到JVM中经过的三个步骤
装载: 查找和导入类或接口的二进制数据
链接: 分别执行 校验,准备,和解析
校验: 检查导入类或接口的二进制数据的正确性;
准备: **给类的静态变量分配并初始化存储空间; **
解析:...
8年前 (2018-10-09) 3115℃ 0评论
0喜欢
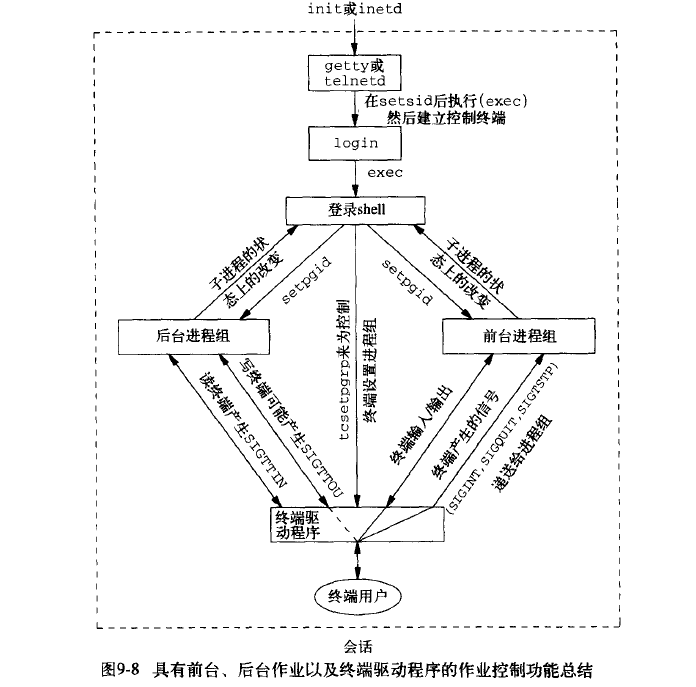
后台进程又叫守护进程,你知道吗?
操作系统中,前台进程和后台进程有什么区别?特征是什么?
后台程序基本上不和用户交互,优先级别稍微低一点 前台的程序和用户交互,需要较高的响应速度,优先级别稍微高一点
直接从后台手工启动一个进程用得比较少一些,除非是该进程甚为耗时,且用户...
8年前 (2018-10-08) 5759℃ 0评论
0喜欢
本文是周明耀技术管理专栏的第四篇文章,今天我们主要讲讲软件研发的流程问题。
写在前面
最近针对技术管理工作写了两篇文章,分别是《程序员, 这是你想要的技术 leader 吗?》和《别人家的技术 leader 是如何建设团队、管理人员、沟通工作的?》,此外,通过一篇文章《这二十个问...
8年前 (2018-09-28) 2938℃ 0评论
0喜欢
原文地址:http://jlongster.com/How-I-Became-Better-Programmer
译者注:本文作者 James Long,前 Mozilla 工程师,NodeJS, ReactJS 社区活跃开发者。NodeJS 著名模板引擎 N...
8年前 (2018-09-28) 3833℃ 0评论
1喜欢
世间很多道理都是相通的,小时候看武侠片里面分不同层次的高手,今天有幸看到软件设计领域其实也有不同层次的高手,软件领域分为四个境界:
第一境界:知器
就是掌握一门或者几门编程语言,会模仿例子来实现程序代码,并且让代码在计算机系统中成功运行起来。达到这个境界的人还不能算是真正意义上...
8年前 (2018-09-28) 3211℃ 0评论
1喜欢
SAP BI商务智能是什么?这是很多SAP基础入门的学员经常问的问题。SAP BI(Business Intelligence)即商务智能,它是一套完整的商业解决方案,用来将企业中现有的数据进行有效的整合,快速准确的提供报表并提出决策依据,帮助企业做出明智的业务经营决...
8年前 (2018-09-27) 4305℃ 0评论
0喜欢
wget --no-check-certificate -c --header "Cookie: oraclelicense=accept-securebackup-cookie" http://do...
8年前 (2018-09-26) 4029℃ 0评论
0喜欢
1.摘要
最近排查了一个比较灵异的线上jvm内存持续增长的问题,排查过程异常艰辛,但是最后竟然是用最简单的办法搞定了……
2.现象
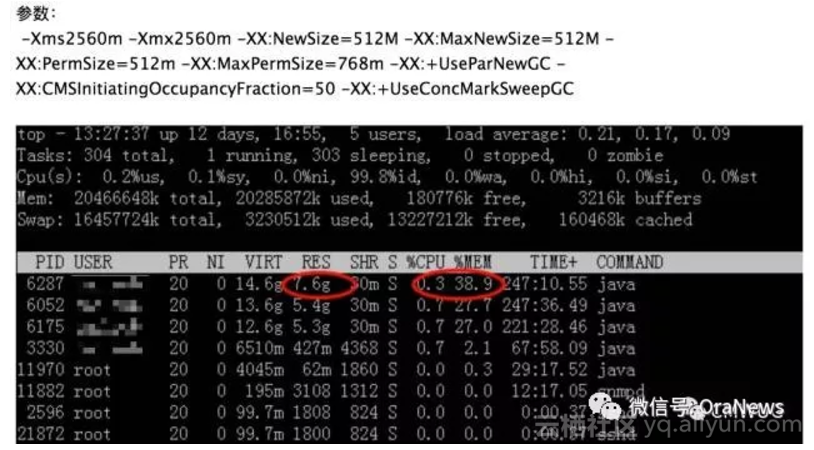
线上机器部署了两个java实例,在运行几天后java开始吃swap空间,java实例的内存占用接近7G,程序响应很慢,重启后又恢复正常。线上配置的堆...
8年前 (2018-09-25) 8107℃ 0评论
3喜欢
我们的一个系统上线后发现内存占用非常高,已分配内存达到11G,而已分配地址空间更是17G了,而根据jmap执行结果发现:
Attaching to process ID 1507, please wait... ...
8年前 (2018-09-25) 7759℃ 0评论
2喜欢
问题描述
通过本文,你应该了解:
1. pmap 命令
2. gdb 命令
3. perf 命令
4. 内存 RSS、VSZ的区别
5. java NMT
这几天遇到一个比较奇怪的问题,觉得有必要和大家分享一下。我们的一个服务,运行在docker上,在某个版...
8年前 (2018-09-25) 4243℃ 0评论
0喜欢
摘要: 故障案例一 系统环境: RHEL 6.8 64-bit(glibc 2.12)、Sun JDK 6u45 64-bit、WLS 10.3.6 故障现象: 这里引用一下客户当时发邮件时提出的问题描述吧。
故障案例一
系统环境:
RHEL 6.8 64-bit(gl...
8年前 (2018-09-25) 4099℃ 0评论
0喜欢
NER(Named Entity Recognition,命名实体识别)又称作专名识别,是自然语言处理中常见的一项任务,使用的范围非常广。命名实体通常指的是文本中具有特别意义或者指代性非常强的实体,通常包括人名、地名、机构名、时间、专有名词等。NER系统就是从非结构化的文本中抽取...
8年前 (2018-09-10) 26721℃ 0评论
26喜欢
Kafka 0.9+增加了一个新的特性Kafka Connect,可以更方便的创建和管理数据流管道。它为Kafka和其它系统创建规模可扩展的、可信赖的流数据提供了一个简单的模型,通过connectors可以将大数据从其它系统导入到Kafka中,也可以从Kafka中导出到其它系统。...
8年前 (2018-09-06) 4408℃ 0评论
0喜欢
在JDK8之前,java编译器会忽略我们编写代码时候设定的参数名,比如在mybatis框架中,我们可以使用@Param注解来让mybatis知道参数名。
public interface DemoMapper { ...
8年前 (2018-09-05) 4282℃ 0评论
1喜欢
虚拟化技术日益普及,基于行业标准的服务器功能越来越强大,加上云计算的出现,这些因素共同导致了企业内外需要加以管理的服务器数量大幅增长。过去我们只要管理内部数据中心里面的物理服务器机架,而现在我们要管理多得多的服务器,它们有可能遍布全球各地。
这时候,数据中心协调和配置管理工具...
8年前 (2018-08-16) 4005℃ 0评论
2喜欢