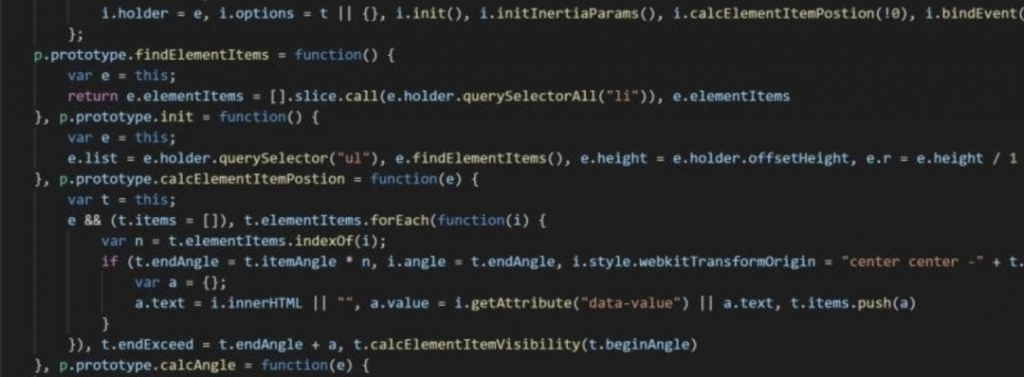
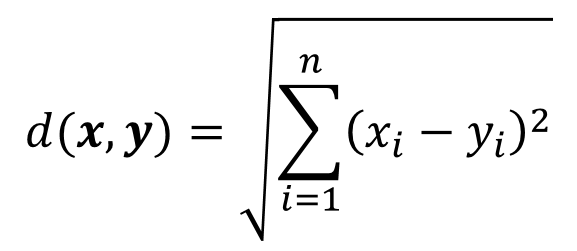这是一个非常关键的业务场景变更。“电厂内部存放电力设备的厂房”与“普通民居”有本质区别:
环境特殊: 高电磁干扰(EMI)、高电压、可能有防爆要求。容错率低: 民居漏水是财产损失,变电站/配电房漏水可能导致短路、跳闸、甚至爆炸(如GIS室、高压开关柜)。监测重点: 不仅要...
water
1个月前 (02-03) 207℃ 0评论
0喜欢
做产品经理总会听到三个文档,可这三个文档到底是做什么的呢?
首先,产品经理三大文档分别是哪三个?
BRD(商业需求文档)MRD(市场需求文档)PRD(产品需求文档)
内容点区别👇:
一、BRD(商业需求文档)
定义:基于商业目...
water
2个月前 (12-31) 416℃ 0评论
0喜欢
我来为您详细介绍服务降级、限流、熔断这三个重要的微服务稳定性概念。在微服务架构中,服务降级、限流 和 熔断 是保障系统稳定性和高可用性的三大核心策略,它们各自解决不同的问题,但常常配合使用。以下是对这三个概念的详细介绍:
✅ 一句话区分(先给你个整体...
water
4个月前 (11-11) 497℃ 0评论
0喜欢
Java 是一种高级编程语言,广泛应用于开发各种类型的应用程序,包括服务端应用。然而,随着应用程序规模和负载的增加,Java 服务性能可能会受到影响。本文将介绍如何进行 Java 服务性能优化,以提高应用程序的响应速度和吞吐量。
分析服务性能问题
在开始进行性能优化...
water
3年前 (2023-02-17) 3063℃ 0评论
2喜欢
ChatGPT是一款由OpenAI开发的语言模型,它是一种人工智能系统,可以模仿人类语言的流畅性和逻辑思维能力。ChatGPT可以通过对大量文本数据的学习,为用户提供自然的对话交互,并以一种类似于人类的方式回答用户的问题。
ChatGPT的设计初衷是帮助人们更轻松地与计算...
water
3年前 (2023-02-16) 3938℃ 0评论
1喜欢
之前做过一个测试,详情见这篇文章《多线程 +1操作的几种实现方式,及效率对比》,当时对这个测试结果很疑惑,反复执行过多次,发现结果是一样的:
单线程下synchronized效率最高(当时感觉它的效率应该是最差才对);AtomicInteger效率最不稳定,不同并发情况下...
water
3年前 (2023-02-07) 4049℃ 0评论
1喜欢
前言
最近遇到几个系统 young gc 时间比较长,在 young gc 长的同时,系统负载也随时升高,因此熟读GC日志以及了解一些Jvm常见调优是必要的。
收获
看完应该有如下收获
熟悉young GC日志每一行啥意思(会看)。了解一些关键GC调优参...
water
3年前 (2023-02-07) 3753℃ 0评论
0喜欢
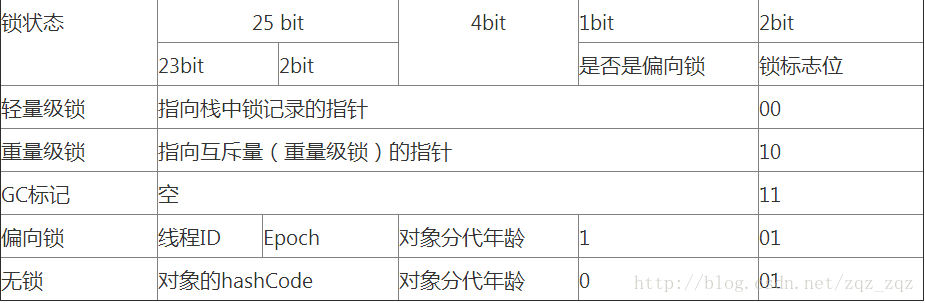
性能调优:
-XX:-OmitStackTraceInFastThrow 去掉优化多次抛异常
-XX:-UseBiasedLocking 去掉偏向锁(锁竞争激烈的场景下加上)
-XX:-UseCounterDecay 禁止JIT调用计数器衰减(默认情况下,每次...
water
3年前 (2023-02-07) 3218℃ 0评论
0喜欢
前言
【本文于2022-5-10日首发于ITPUB微信公众号平台】
该篇文章是我第一次跟DTCC合作编写的,整篇文章大概8000字,可能花您15分钟阅读。我和DTCC的韩楠老师,共花7了天时间,每天把该文章打磨到晚上12点,在这非常感谢编辑老师的负责与付出。...
water
4年前 (2022-09-14) 3024℃ 0评论
1喜欢
一、用户相关
1、DAU(Daily Active User)日活跃用户数量
说明:通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户)
2、MAU(Monthly Active User)月活跃用户人数
说明:通常统计一个月(...
water
4年前 (2022-09-14) 7968℃ 0评论
2喜欢
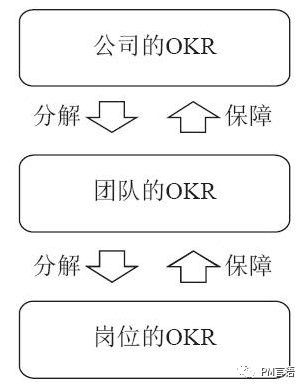
“ 当我们在学校的时候,没有人告诉关于我们还需要学习很多首字母缩略词。在技术和产品领域尤其如此。OKR、KPI、UX、UI、QA、CTR、CVR、ROI等等。而今天我们主要关注两个指标,OKR和KPI。在互联网工作每一个人被要求设定自己的OKR或KPI。OKR和KPI是用于设定...
water
4年前 (2022-09-14) 2992℃ 0评论
0喜欢
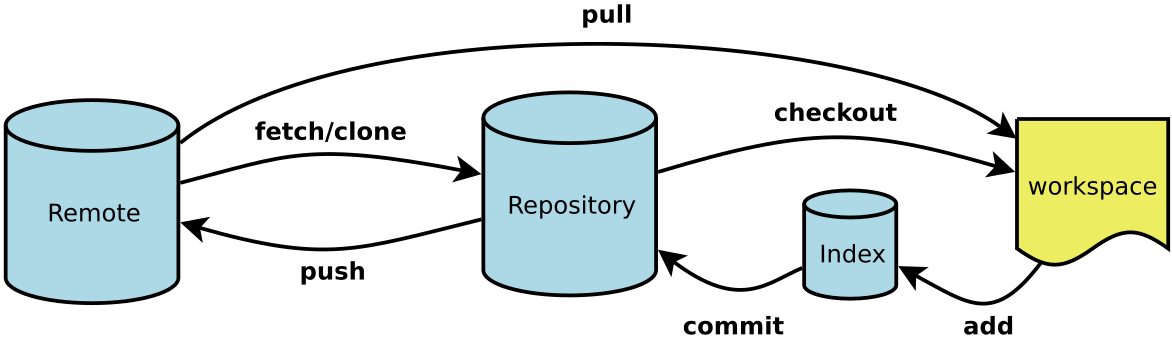
我每天使用 Git ,但是很多命令记不住。
一般来说,日常使用只要记住下图6个命令,就可以了。但是熟练使用,恐怕要记住60~100个命令。
下面是我整理的常用 Git 命令清单。几个专用名词的译名如下。
Workspace:工作区Index / Sta...
water
4年前 (2022-09-14) 2627℃ 0评论
0喜欢
一、引言
HBase其存储和读写的高性能,作为Nosql数据库的一员,HBase查询只能通过其Rowkey来查询(Rowkey用来表示唯一一行记录),Rowkey设计的优劣直接影响读写性能。HBase中的数据是按照Rowkey的ASCII字典顺序进行全局排序的,有伙伴可能...
water
4年前 (2022-09-08) 2905℃ 0评论
1喜欢
春节期间,高速上动不动就堵车,这是一种“背压”的现象。背压(back pressure),也叫“反压”,指的是下游系统处理过慢,导致上游系统阻塞的现象。我们来聊聊背压后面的流控吧。
流控策略
如上图,系统中存在三方:生产者(Producer)产生数据,通过管道(Pi...
water
4年前 (2022-09-05) 4034℃ 0评论
1喜欢
互联网行业职位介绍1、PM
项目经理( Project Manager )
从职业角度,是指企业建立以项目经理责任制为核心,对项目实行质量、安全、进度、成本管理的责任保证体系和全面提高项目管理水平设立的重要管理岗位。项目经理是为项目的成功策划和执行负总责的人。
...
water
4年前 (2022-07-13) 3623℃ 0评论
13喜欢
垃圾优先型垃圾回收器 (G1 GC) 是适用于 Java HotSpot VM 的低暂停、服务器风格的分代式垃圾回收器。G1 GC 使用并发和并行阶段实现其目标暂停时间,并保持良好的吞吐量。当 G1 GC 确定有必要进行垃圾回收时,它会先收集存活数据最少的区域(垃圾优...
water
4年前 (2022-07-13) 1669℃ 0评论
0喜欢
转载自:聂晓龙(率鸽) 阿里开发者
前言
前天回家路上,有辆车强行插到前面的空位,司机大哥吐槽“加塞最可恶了”,我问“还有更可恶的吗”,司机大哥淡定说道“不让自己加塞的”。似乎和我们很类似,我们程序员届也有这2件相辅相成的事:最讨厌别人不写注释,更讨厌让自己写注释...
water
4年前 (2022-06-14) 2270℃ 0评论
6喜欢
计算化学中有时会要求我们计算两个向量的相似度,如做聚类分析时需要计算两个向量的距离,用分子指纹来判断两个化合物的相似程度,用夹角余弦判断两个描述符的相似程度等。计算向量间相似度的方法有很多种,本文将简单介绍一些常用的方法。这些方法相关的代码已经提交到github仓库
h...
water
4年前 (2022-06-13) 3454℃ 0评论
0喜欢
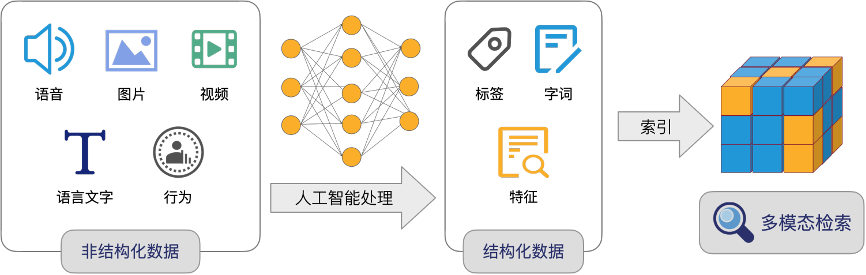
链接:https://zhuanlan.zhihu.com/p/364923722
引用文章[7]的开篇,来表示什么是: 向量化搜索人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些...
water
4年前 (2022-06-09) 6262℃ 0评论
0喜欢
1 C10K问题
大家都知道互联网的基础就是网络通信,早期的互联网可以说是一个小群体的集合。互联网还不够普及,用户也不多。一台服务器同时在线100个用户估计在当时已经算是大型应用了。所以并不存在什么C10K的难题。互联网的爆发期应该是在www网站,浏览器,雅虎出现后。最早...
water
4年前 (2022-06-09) 2300℃ 0评论
2喜欢