什么是中文分词
与大部分印欧语系的语言不同,中文在词与词之间没有任何空格之类的显示标志指示词的边界。因此,中文分词是很多自然语言处理系统中的基础模块和首要环节。
下面以jieba的示例给读者一个对分词的感性认识。
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 我/ 来到/ 北京/ 清华大学 【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
中文分词的方法和评价指标
从20世纪80年代或更早的时候起,学者们研究了很多的分词方法,这些方法大致可以分为三大类:
-
基于词表的分词方法
-
正向最大匹配法(forward maximum matching method, FMM)
-
逆向最大匹配法(backward maximum matching method, BMM)
-
N-最短路径方法
基于统计模型的分词方法
-
基于N-gram语言模型的分词方法
基于序列标注的分词方法
-
基于HMM的分词方法
-
基于CRF的分词方法
-
基于词感知机的分词方法
-
基于深度学习的端到端的分词方法
在中文分词领域,比较权威且影响深远的评测有 SIGHAN – 2nd International Chinese Word Segmentation Bakeoff。它提供了2份简体中文和2份繁体中文的分词评测语料。
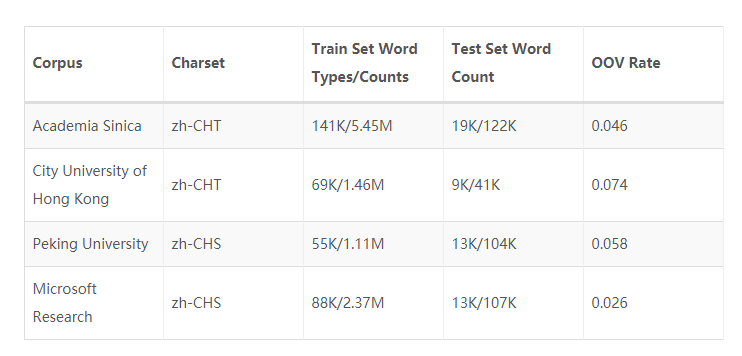
Sighan中采用的评价指标包括:
-
准确率(Precision)
-
召回率(Recall)
-
F-测度(F-measure)
-
未登录词的召回率(ROOV)
-
词典词的召回率(RIV)
各指标计算公式如下:
各分词方法的细节
正向最大匹配法(FMM)

正向最大匹配法,顾名思义,对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。正向最大匹配法是基于词典的分词方法,其分词原理是:单词的颗粒度越大,所能表示的含义越确切。
负向最大匹配法(BMM)
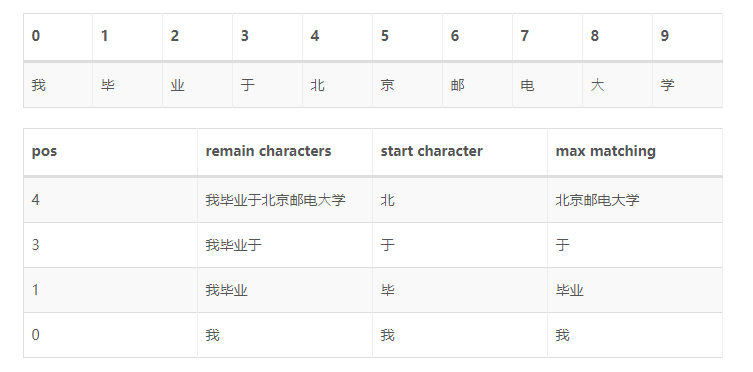
反向最大匹配法的基本原理与正向最大匹配法类似,只是分词顺序变为从右至左。容易看出,FMM或BMM对于一些有歧义的词处理能力一般。举个例子:结婚的和尚未结婚的,使用FMM很可能分成结婚/的/和尚/未/结婚/的;为人民办公益,使用BMM可能会分成为人/民办/公益。
虽然在部分文献和软件实现中指出,由于中文的性质,反向最大匹配法优于正向最大匹配法。在成熟的工业界应用上几乎不会直接使用FMM、BMM作为分词模块的实现方法。
基于N-gram语言模型的分词方法
由于歧义的存在,一段文本存在多种可能的切分结果(切分路径),FMM、BMM使用机械规则的方法选择最优路径,而N-gram语言模型分词方法则是利用统计信息找出一条概率最大的路径。
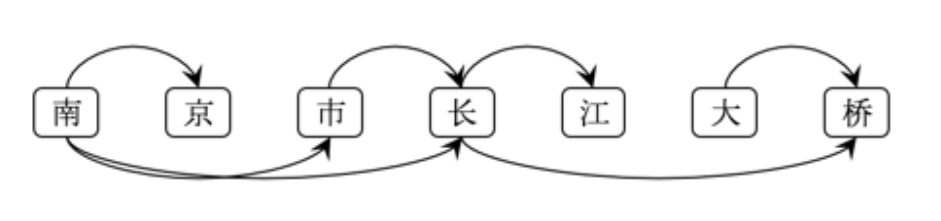
上图为南京市长江大桥的全切分有向无环图(DAG)。可以看到,可能的切分路径有:
-
南京/市/长江/大桥
-
南京/市/长江大桥
-
南京市/长江/大桥
-
南京市/长江大桥
-
南京/市长/江/大桥
-
南京/市长/江大桥
-
南京市长/江/大桥
-
南京市长/江大桥
-
…
假设随机变量S为一个汉字序列,W是S上所有可能的切分路径。对于分词,实际上就是求解使条件概率P(W∣S)最大的切分路径W∗,即
根据贝叶斯公式,
由于P(S)为归一化因子,P(S∣W)恒为1,因此只需要求解P(W)。
P(W)使用N-gram语言模型建模,定义如下(以Bi-gram为例):
至此,各切分路径的好坏程度(条件概率P(W∣S))可以求解。简单的,可以根据DAG枚举全路径,暴力求解最优路径;也可以使用动态规划的方法求解,jieba中不带HMM新词发现的分词,就是DAG + Uni-gram的语言模型 + 后向DP的方式进行的。
基于HMM的分词方法
接下来介绍的几种分词方法都属于由字构词的分词方法,由字构词的分词方法思想并不复杂,它是将分词问题转化为字的分类问题(序列标注问题)。从某些层面讲,由字构词的方法并不依赖于事先编制好的词表,但仍然需要分好词的训练语料。
规定每个字有4个词位:
-
词首 B
-
词中 M
-
词尾 E
-
单字成词 S

由于HMM是一个生成式模型,X为观测序列,Y为隐序列。
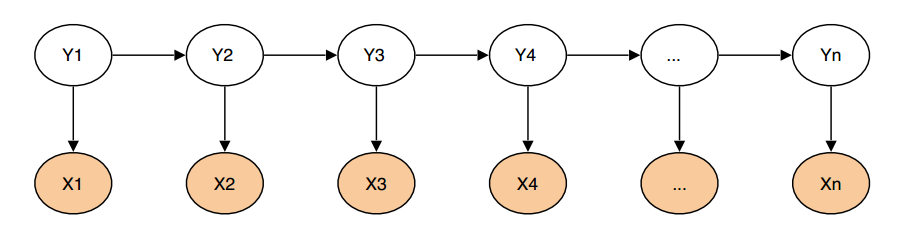
熟悉HMM的同学都知道,HMM有三类基本问题:
-
预测(filter):已知模型参数和某一特定输出序列,求最后时刻各个隐含状态的概率分布,即求 P(x(t) ∣ y(1),⋯,y(t))。通常使用前向算法解决.
-
平滑(smoothing):已知模型参数和某一特定输出序列,求中间时刻各个隐含状态的概率分布,即求 P(x(k) ∣ y(1),⋯,y(t)),k<t。通常使用forward-backward 算法解决.
-
解码(most likely explanation): 已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列. 即求 P([x(1)⋯x(t)] ∣ [y(1)⋯,y(t)]), 通常使用Viterbi算法解决.
分词就对应着HMM的解码问题,模型参数(转移矩阵,发射矩阵)可以使用统计方法计算得到,原始文本为输出序列,词位是隐状态序列,使用Viterbi算法求解即可。具体方法请参照参考资料#2。
jieba的新词模式就是使用HMM识别未登录词的,具体做法是:针对不在词表中的一段子文本,使用HMM分词,并把HMM的分词结果加入到原始分词结果中。
基于CRF的分词方法
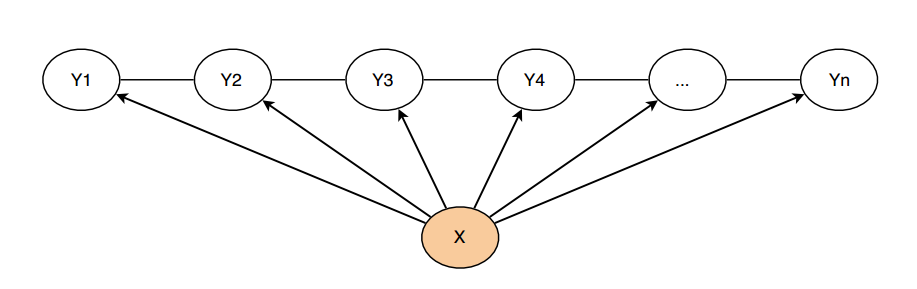
与HMM不同,CRF是一种判别式模型,CRF通过定义条件概率P(Y∣X)来描述模型。基于CRF的分词方法与传统的分类模型求解很相似,即给定feature(字级别的各种信息)输出label(词位)。
简单来说,分词所使用的是Linear-CRF,它由一组特征函数组成,包括权重λ和特征函数f,特征函数f的输入是整个句子s、当前posi、前一个词位li−1,当前词位li。
引自参考资料#3,以CRF在词性标注上的应用,给大家一个特征函数的感性认识。
-
f1(s,i,li,li−1)=1,如果li是副词且第i个单词以"-ly"结尾;否则f1=0。该特征函数实际上描述了英语中副词“常常以-ly结尾”的特点,对应的权重λ1应该是个较大的正数。
-
f4(s,i,li,li−1)=1,如果li−1是介词且li也是介词,否则f4=0。对应的权重λ4是个较大的负数,表明英语语法中介词一般不连续出现。
感性地说,CRF的一组特征函数其实就对应着一组判别规则(特征函数),并且该判别规则有不同的重要度(权重)。在CRF的实现中,特征函数一般为二值函数,其量纲由权重决定。在开源实现CRF++中,使用者需要规定一系列特征模板,然后CRF++会自动生成特征函数并训练、收敛权重。
与HMM比,CRF存在以下优点:
-
CRF可以使用输入文本的全局特征,而HMM只能看到输入文本在当前位置的局部特征
-
CRF是判别式模型,直接对序列标注建模;HMM则引入了不必要的先验信息
基于深度学习的端到端的分词方法
最近,基于深度神经网络的序列标注算法在词性标注、命名实体识别问题上取得了优秀的进展。词性标注、命名实体识别都属于序列标注问题,这些端到端的方法可以迁移到分词问题上,免去CRF的特征模板配置问题。但与所有深度学习的方法一样,它需要较大的训练语料才能体现优势。
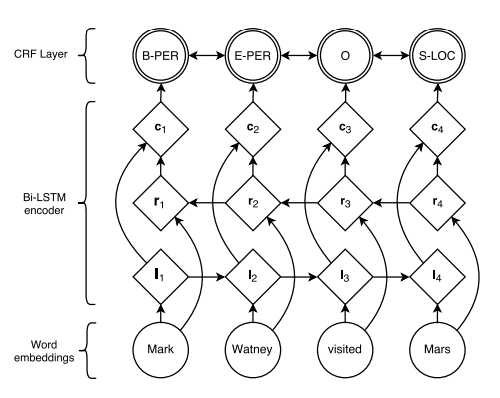
BiLSTM-CRF(参考资料#4)的网络结构如上图所示,输入层是一个embedding层,经过双向LSTM网络编码,输出层是一个CRF层。下图是BiLSTM-CRF各层的物理含义,可以看见经过双向LSTM网络输出的实际上是当前位置对于各词性的得分,CRF层的意义是对词性得分加上前一位置的词性概率转移的约束,其好处是引入一些语法规则的先验信息。
从数学公式的角度上看:
其中,A是词性的转移矩阵,P是BiLSTM网络的判别得分。
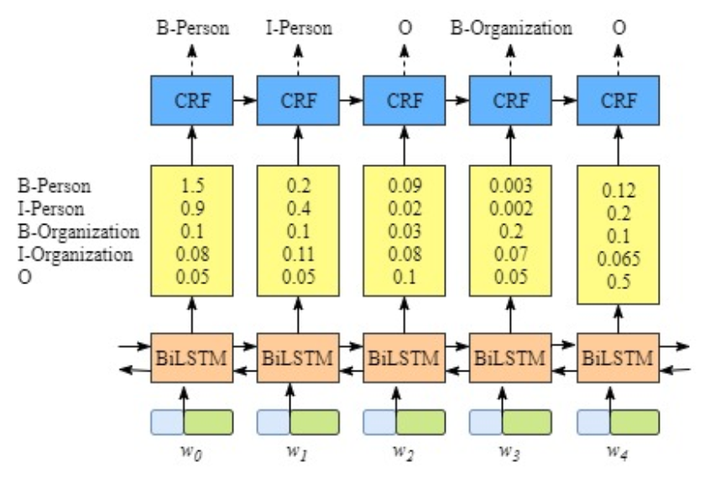
因此,训练过程就是最大化正确词性序列的条件概率P(y∣X)。
类似的工作还有LSTM-CNNs-CRF(参考资料#5)。
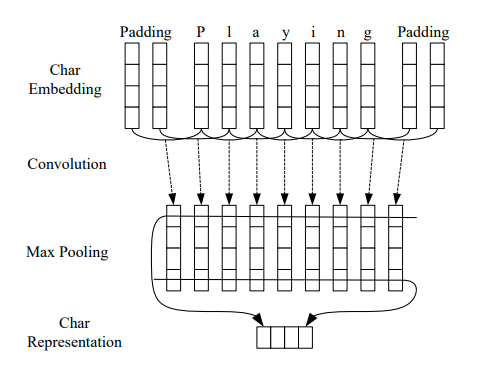
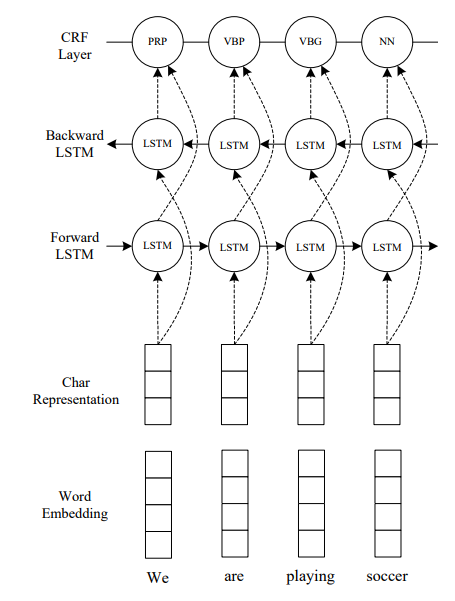
更多精彩内容,请关注我的个人博客。
参考资料
-
成庆, 宗. 统计自然语言处理[M]. 清华大学出版社, 2008.
-
Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition[J]. 2016:260-270.
-
Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnns-crf[J]. arXiv preprint arXiv:1603.01354, 2016.