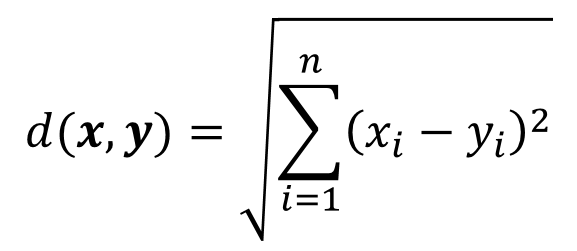我来为您详细介绍服务降级、限流、熔断这三个重要的微服务稳定性概念。在微服务架构中,服务降级、限流 和 熔断 是保障系统稳定性和高可用性的三大核心策略,它们各自解决不同的问题,但常常配合使用。以下是对这三个概念的详细介绍:
✅ 一句话区分(先给你个整体...
water
4个月前 (11-11) 514℃ 0评论
0喜欢
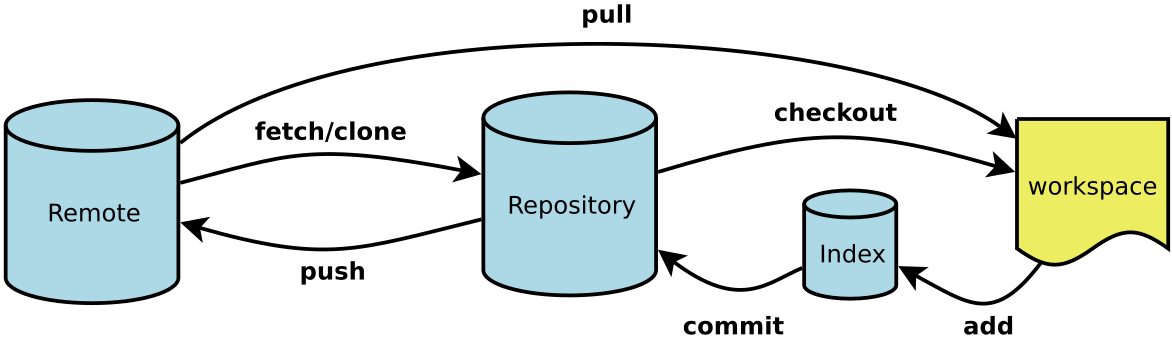
我每天使用 Git ,但是很多命令记不住。
一般来说,日常使用只要记住下图6个命令,就可以了。但是熟练使用,恐怕要记住60~100个命令。
下面是我整理的常用 Git 命令清单。几个专用名词的译名如下。
Workspace:工作区Index / Sta...
water
4年前 (2022-09-14) 2637℃ 0评论
0喜欢
一、引言
HBase其存储和读写的高性能,作为Nosql数据库的一员,HBase查询只能通过其Rowkey来查询(Rowkey用来表示唯一一行记录),Rowkey设计的优劣直接影响读写性能。HBase中的数据是按照Rowkey的ASCII字典顺序进行全局排序的,有伙伴可能...
water
4年前 (2022-09-08) 2918℃ 0评论
1喜欢
转载自:聂晓龙(率鸽) 阿里开发者
前言
前天回家路上,有辆车强行插到前面的空位,司机大哥吐槽“加塞最可恶了”,我问“还有更可恶的吗”,司机大哥淡定说道“不让自己加塞的”。似乎和我们很类似,我们程序员届也有这2件相辅相成的事:最讨厌别人不写注释,更讨厌让自己写注释...
water
4年前 (2022-06-14) 2278℃ 0评论
6喜欢
计算化学中有时会要求我们计算两个向量的相似度,如做聚类分析时需要计算两个向量的距离,用分子指纹来判断两个化合物的相似程度,用夹角余弦判断两个描述符的相似程度等。计算向量间相似度的方法有很多种,本文将简单介绍一些常用的方法。这些方法相关的代码已经提交到github仓库
h...
water
4年前 (2022-06-13) 3467℃ 0评论
0喜欢
链接:https://zhuanlan.zhihu.com/p/364923722
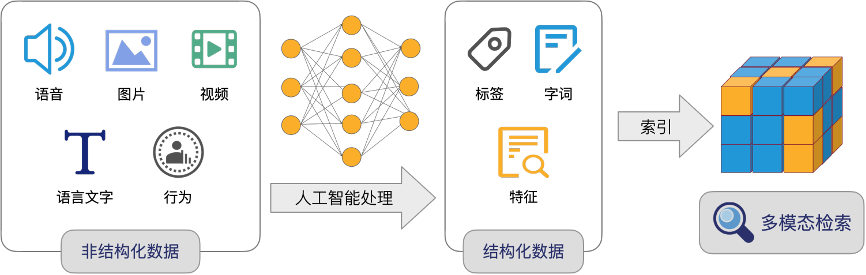
引用文章[7]的开篇,来表示什么是: 向量化搜索人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。
这些...
water
4年前 (2022-06-09) 6293℃ 0评论
0喜欢
1 C10K问题
大家都知道互联网的基础就是网络通信,早期的互联网可以说是一个小群体的集合。互联网还不够普及,用户也不多。一台服务器同时在线100个用户估计在当时已经算是大型应用了。所以并不存在什么C10K的难题。互联网的爆发期应该是在www网站,浏览器,雅虎出现后。最早...
water
4年前 (2022-06-09) 2310℃ 0评论
2喜欢
本文用 19 张思维导图描述微服务相关的概念和架构,建议收藏。包括什么是微服务、架构演进、微服务架构、微服务解决方案、SpringCloud概览、Eureka、Ribbon、Feign、Hystrix、Zuul、Gateway、Config、Bus、OAuth2、Sleuth、...
water
4年前 (2022-03-24) 2208℃ 0评论
0喜欢
Spring Cloud的主要组件
Spring Cloud是目前微服务架构领域的翘楚,无数的书籍博客都在讲解这个技术,实际上,Spring Cloud是一个全家桶式的技术栈,包含了很多组件。本文先从其最核心的几个组件入手,来剖析一下其底层的工作原理。也就是Eureka、...
water
4年前 (2022-03-24) 2351℃ 0评论
0喜欢
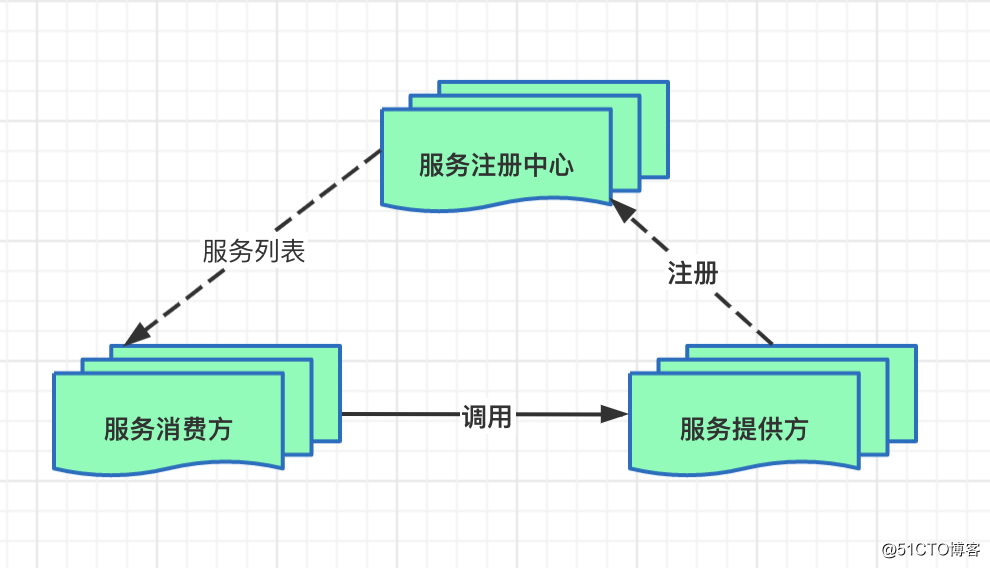
注册中心简介
微服务架构中,注册中心是最核心的基础服务之一,注册中心可以看做是微服务架构中的通信中心,当一个服务去请求另一个服务时,通过注册中心可以获取该服务的状态,地址等核心信息。
服务注册主要关系到三大角色:服务提供者、服务消费者、注册中心。
流程...
water
4年前 (2022-03-23) 2815℃ 0评论
1喜欢
Superset介绍及使用说明Superset简介Apache Superset是Airbnb开源的数据挖掘平台。支持丰富的数据源连接,多种可视化方式,并能够对用户实现细粒度的权限控制。该工具主要特点是可自助分析、自定义仪表盘、分析结果可视化(导出)、用户/角色权限控制,还集成...
water
4年前 (2021-11-29) 3903℃ 0评论
2喜欢
git初始化
首先下载安装git,配置好公私密钥和github
git命令
git initgit remote add origin [远程库地址]git pull origin mastergit add .git commit -m “注释&...
water
4年前 (2021-11-26) 2468℃ 0评论
1喜欢
1.单元测试:是对软件中最小可测试单元(人为规定的最小必测功能模块)进行检查和验证。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
2.集成测试:也叫组装测试或联合测试。在单元测试的基础上将所有模块按照要...
water
4年前 (2021-11-19) 4801℃ 0评论
6喜欢
作者:@pdai本文为作者原创,转载请注明出处:https://www.cnblogs.com/pengdai/p/13677095.html
最为常见的是代码中使用很多的if/else,或者switch/case;如何重构呢?方法特别多,本文带你学习其中的技巧。
...
water
4年前 (2021-11-11) 2737℃ 0评论
2喜欢
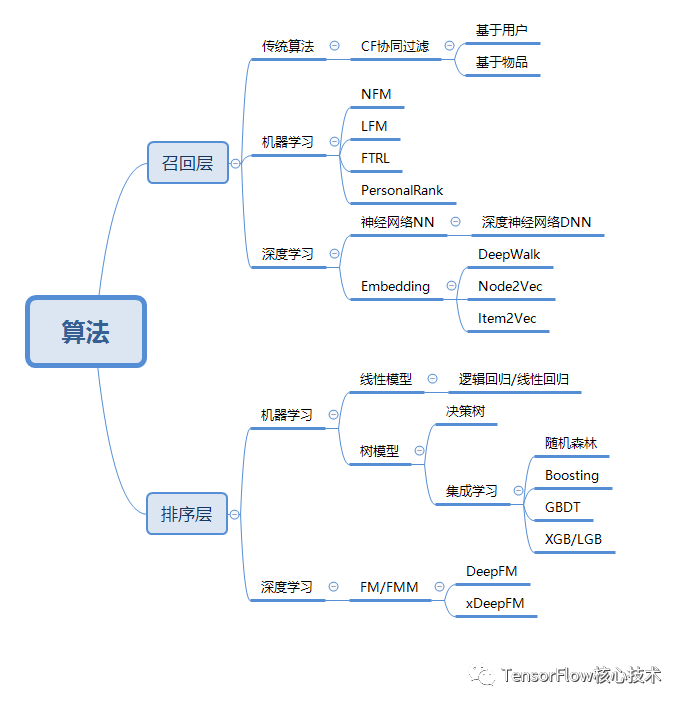
知乎上链接:https://zhuanlan.zhihu.com/p/115690499
目前工业界常用的召回排序模型主要有:
召回模型
(1)基于内容的召回CB(Content–Base)
使用item之间的相似性来推荐与用户喜欢的item...
water
4年前 (2021-11-09) 4023℃ 0评论
0喜欢
我为什么要写这篇
近来,和不少初学Spring或Spring Boot的小伙伴私信交流了关于项目目录结构划分和代码分层的问题。
很多小伙伴表示网上下载下来的开源项目看不懂,项目结构和代码分层看得很蒙,不知道应该以一个什么样的思路去学习和吸收别人的项目。
好,今...
water
4年前 (2021-10-20) 2468℃ 0评论
4喜欢
分天下为三十六郡,郡置守,尉,监” —— 《史记·秦始皇本纪》
所有用Maven管理的真实的项目都应该是分模块的,每个模块都对应着一个pom.xml。它们之间通过继承和聚合(也称作多模块,multi-module)相互关联。那么,为什么要这么做呢?我们明明在开发一个项目,...
water
4年前 (2021-10-20) 2321℃ 0评论
0喜欢
随着项目的不断发展,需求的不断细化与添加,代码越来越多,结构也越来越复杂,这时候就会遇到各种问题
不同方面的代码之间相互耦合,这时候一系统出现问题很难定位到问题的出现原因,即使定位到问题也很难修正问题,可能在修正问题的时候引入更多的问题。多方面的代码集中在一个整体结构中,...
water
4年前 (2021-10-20) 2529℃ 0评论
0喜欢
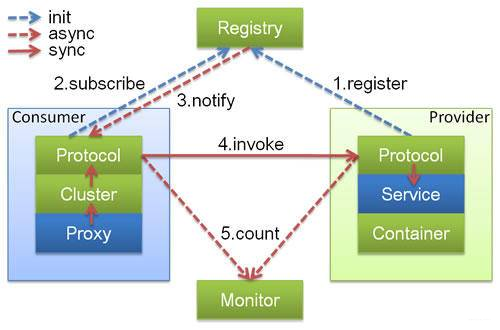
RPC框架主要组成:
通信框架通信协议序列化和反序列化格式
1 分类
RPC框架主要分为:
1.1 绑定语言平台
1.1.1 Dubbo
国内最早开源的RPC框架,由阿里巴巴公司开发并于2011年末对外开源,仅支持Java
架构
...
water
4年前 (2021-10-19) 2411℃ 0评论
0喜欢
幂等设计在分布式系统设计中占有很重要的地位,是实现数据一致性和事务完整性的重要手段。近期在优化交易系统,系统中很多地方用到了幂等设计,遂对其进行了总结。
幂等定义:
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,...
water
5年前 (2021-07-28) 2777℃ 0评论
2喜欢